A recommendation system, is a system that can predict a rating for a user-item pair, where this user has never interacted with the item before.
In other words, is users of a user can give preferences for items/products in the sense of a star system (1-5 stars like NetFlix) or a thumbs-up/thumbs-down like YouTube, one can generate a rating matrix consisting of users and items. And each cell then has a rating value if the user has rated this particular item.
| User/product matrix | James | Peter | Anna | Victoria |
| Blue pants | 5 | 3 | 0 | 1 |
| Red hat | 4 | 0 | 0 | 1 |
| Black shoes | 1 | 1 | 0 | 5 |
| Computer mouse | 1 | 0 | 0 | 4 |
| Yellow t-shirt | 0 | 1 | 5 | 4 |
The table above, is called a ratings matrix, where a value above 0 is a rating defined by the user. A rating of 0 means the user has never encountered the product before.
We now wish to calculate all the cells with 0’s – This is where Matrix Factorization is useful.
Let’s do some maths’
We have a set of users 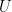


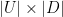

We now need to find two matrices 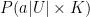
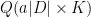

So each row of 

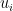

We just need to find 
I’m going to use Gradient Descent – initialize the two matrices with some values, and calculate how different their product is to 
The squared error can be calculated by:

We want to minimize this error, and we want to know in which direction this error goes.
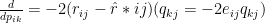
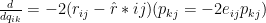
We now know in which direction to go, to minimize the error (i.e. the gradient) for both 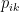
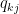

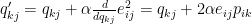
Where 
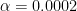
Using the above update rules we can iteratively perform the operation until a convergence.

Now we have the factorization done, which is fine. – We can although run into a problem with over-fitting the model.
To avoid that, we introduce a regularization step:

Where 

So the new update rules are:

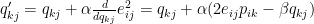
Implementation in PHP
Running the above PHP implementation you will get the output:
| User/product matrix | James | Peter | Anna | Victoria |
| Blue pants | 5.01 | 2.87 | 4.92 | 0.99 |
| Red hat | 3.94 | 2.25 | 4.02 | 0.99 |
| Black shoes | 1.10 | 0.73 | 4.63 | 4.95 |
| Computer mouse | 0.94 | 0.62 | 3.76 | 3.97 |
| Yellow t-shirt | 2.22 | 1.35 | 4.88 | 4.04 |
Where all bold numbers was 0’s in the ratings matrix.
The only thing you need to do, is to use some kind of similarity function (Tanimoto, Pearson, K-NN) to find which items to recommend.
(I have to stop this guide now – it’s already too long) – I hope you gained some knowledge from this, or at least you can use my implementation in your system.
The PHP implementation is written by me, but taken from a Python implementation from here
Thanks a lot! Perfect and fast!